1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
| import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import java.io.*;
import java.net.URL;
import java.util.List;
import java.util.stream.Collectors;
public class Reptile {
static String WEB_URL = "https://www.3gbizhi.com/tag/dongman/";
public static void main(String[] args) throws IOException {
Connection connection = Jsoup
.connect(WEB_URL)
.ignoreContentType(true)
.timeout(60000);
Document document = connection.get();
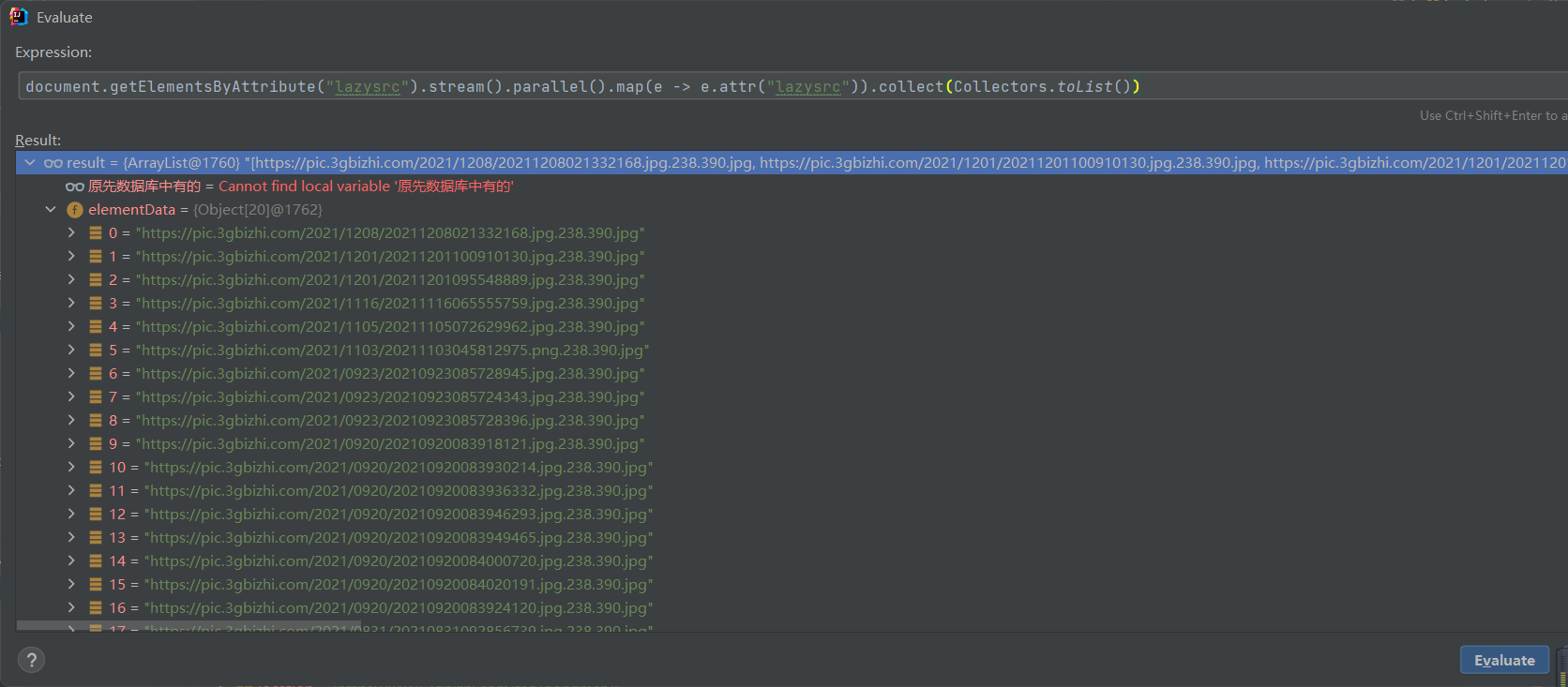
List<String> srcs = document.getElementsByAttribute("lazysrc").stream().parallel().map(e -> e.attr("lazysrc")).collect(Collectors.toList());
srcs.forEach(imgUrl -> {
String imgUrlClear = imgUrl.substring(0, imgUrl.lastIndexOf(".238.390.jpg"));
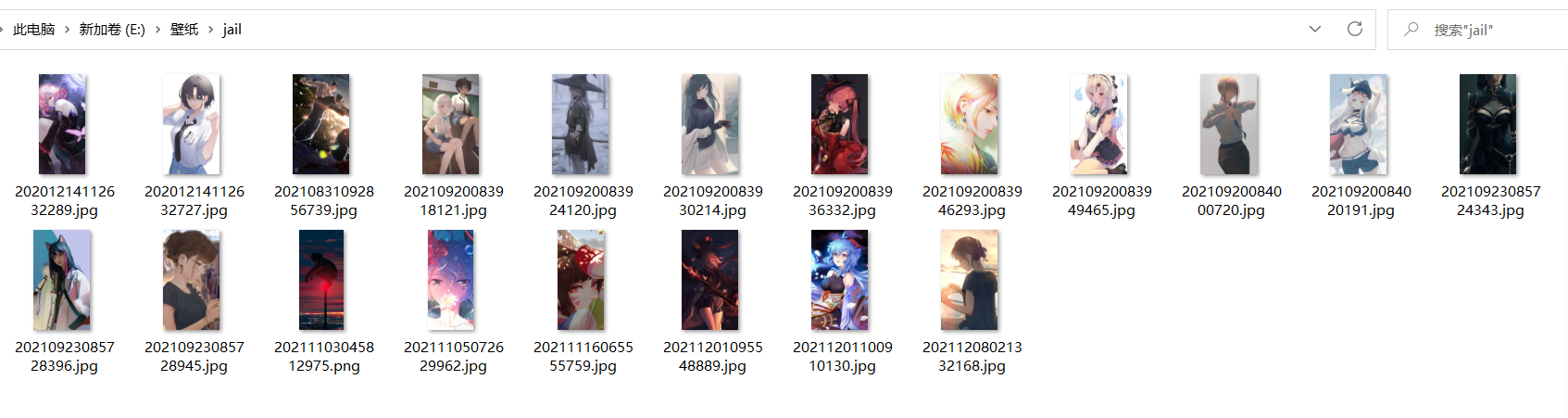
downloadPicture(imgUrlClear, "E:\\壁纸\\jail\\" + imgUrlClear.substring(imgUrl.lastIndexOf("/") + 1));
});
}
public static void downloadPicture(String imageUrl, String path) {
URL url = null;
try {
url = new URL(imageUrl);
DataInputStream dataInputStream = new DataInputStream(url.openStream());
FileOutputStream fileOutputStream = new FileOutputStream(new File(path));
ByteArrayOutputStream output = new ByteArrayOutputStream();
byte[] buffer = new byte[4096];
int length;
while ((length = dataInputStream.read(buffer)) > 0) {
output.write(buffer, 0, length);
}
fileOutputStream.write(output.toByteArray());
dataInputStream.close();
fileOutputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
|